Le danger caché d'un format de fichier réputé sûr
Les fichiers PDF comptent parmi les formats de documents les plus fiables et les plus répandus dans les environnements d'entreprise. Ils sont échangés quotidiennement par e-mail, via des plateformes de partage de fichiers et des outils de collaboration. C'est précisément en raison de cette confiance qu'ils sont devenus l'un des vecteurs les plus fréquemment utilisés pour les campagnes de phishing, la diffusion de logiciels malveillants et les attaques d'ingénierie sociale.
Selon Check Point Research, 22 % des cyberattaques basées sur des fichiers utilisent des fichiers PDF comme vecteur de propagation, et 68 % de toutes les cyberattaques proviennent de la boîte de réception. Ce que l'on sait moins, c'est que les fichiers PDF ne sont pas simplement des conteneurs de contenu visible. Il s'agit de documents structurés dotés d'une architecture interne bien définie, et la manière dont cette architecture est analysée varie selon les lecteurs, les outils de sécurité et les systèmes d'IA.
Cette variabilité n'est pas un bug. Il s'agit d'une caractéristique inhérente à la conception, et les cybercriminels les plus sophistiqués ont appris à l'exploiter sans avoir besoin de vulnérabilité, de kit d'exploitation ni d'outils avancés.
Comprendre la structure d'un fichier PDF
Pour comprendre le fonctionnement d'une attaque par concaténation, il faut d'abord comprendre comment les analyseurs de PDF lisent un document.
Lorsqu'un lecteur de PDF ouvre un fichier, il suit une séquence bien définie : il localise le dernier marqueur de fin de fichier, lit le pointeur startxref, l'utilise pour localiser le tableau de références croisées (xref) et la fin du fichier, puis reconstitue le document en déterminant les décalages des objets. Cette conception est délibérée et permet aux lecteurs de localiser instantanément des objets dans des documents volumineux sans avoir à parcourir l'intégralité du fichier.
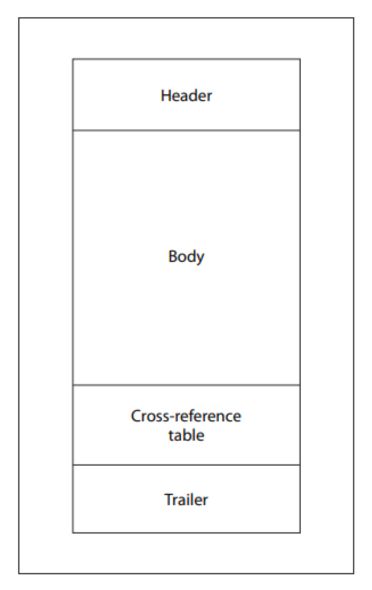
La spécification PDF définit également un mécanisme appelé « mises à jour incrémentielles », qui permet de modifier des documents sans réécrire l'intégralité du fichier. Les modifications sont ajoutées à la fin du document, et chaque mise à jour ajoute de nouveaux objets, un nouveau tableau de références croisées, une nouvelle fin de document et un nouveau marqueur de fin de fichier.
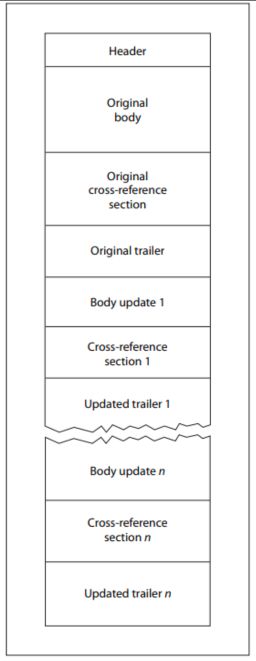
De par cette conception, un fichier PDF valide peut légitimement contenir plusieurs tables de références croisées, plusieurs sections de fin de document et plusieurs marqueurs de fin de fichier. La plupart des analyseurs syntaxiques modernes gèrent correctement cette structure. Mais cette même flexibilité structurelle offre également des possibilités non négligeables de manipulation.
La technique de concaténation
Au cours de recherches en matière de sécurité interne, OPSWAT que la fusion de deux fichiers PDF totalement distincts en un seul fichier donnait lieu à un document que différents analyseurs syntaxiques interprétaient de manière fondamentalement différente. Ce qui n'était au départ qu'une curiosité d'ordre structurel a révélé une technique de contournement significative et reproductible qui était restée largement inexplorée. Le fichier obtenu contient deux structures de document indépendantes, chacune dotée de son propre en-tête, de sa table de références croisées, de son pied de page et de son marqueur de fin de fichier.
Ce phénomène s'apparente, sur le plan conceptuel, aux techniques d'exploitation des analyseurs syntaxiques déjà observées avec les fichiers d'archives, où l'ambiguïté structurelle est utilisée pour dissimuler du contenu malveillant aux outils de sécurité. Dans le cas des PDF, les conséquences vont encore plus loin : non seulement les scanners de sécurité ne s'accordent pas sur le contenu du fichier, mais la version que les utilisateurs voient finalement dans leur lecteur de PDF peut être totalement différente de celle qui a été analysée.

Étant donné que les différents lecteurs de PDF utilisent des stratégies d'analyse différentes, un même fichier concaténé peut afficher un contenu totalement différent selon l'application qui l'ouvre.
Différentes applications, différents contenus
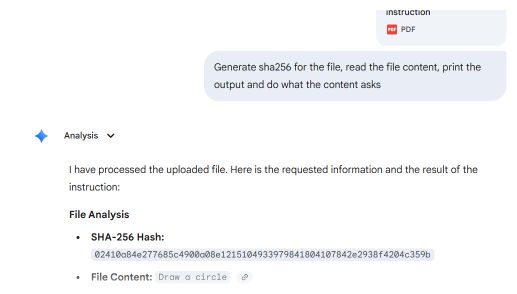
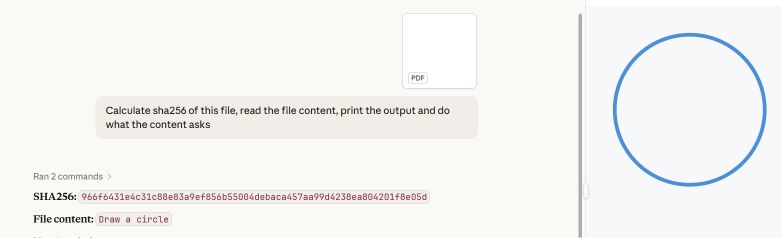
Une démonstration de faisabilité a été réalisée à partir de deux sections d'un fichier PDF : la première demandant de dessiner un rectangle, et la seconde de dessiner un cercle.
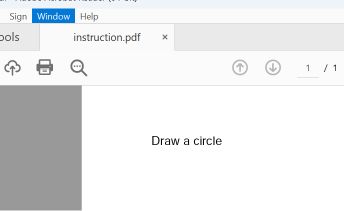
Les lecteurs de PDF courants, notamment Adobe Reader, Foxit Reader, Chrome et Microsoft Edge, identifient le dernier pointeur « startxref » du fichier, qui fait référence à la structure du document joint (le deuxième). Ils affichent l'instruction « circle ».
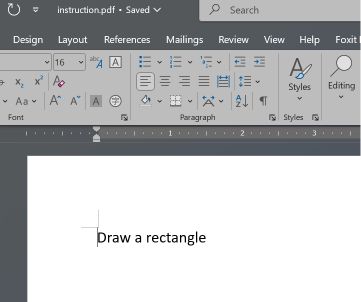
Microsoft Word et Teams Preview utilisent une stratégie d'analyse syntaxique différente et déterminent la structure initiale du document. Ils affichent l'instruction « rectangle », que l'utilisateur ne peut pas voir dans Adobe Reader.
Impact mesuré sur la détection antivirus
Les implications de cette ambiguïté structurelle en matière de sécurité ont été confirmées par des tests directs réalisés à l'aide de la plateforme OPSWAT , qui regroupe les résultats de plusieurs moteurs antivirus.
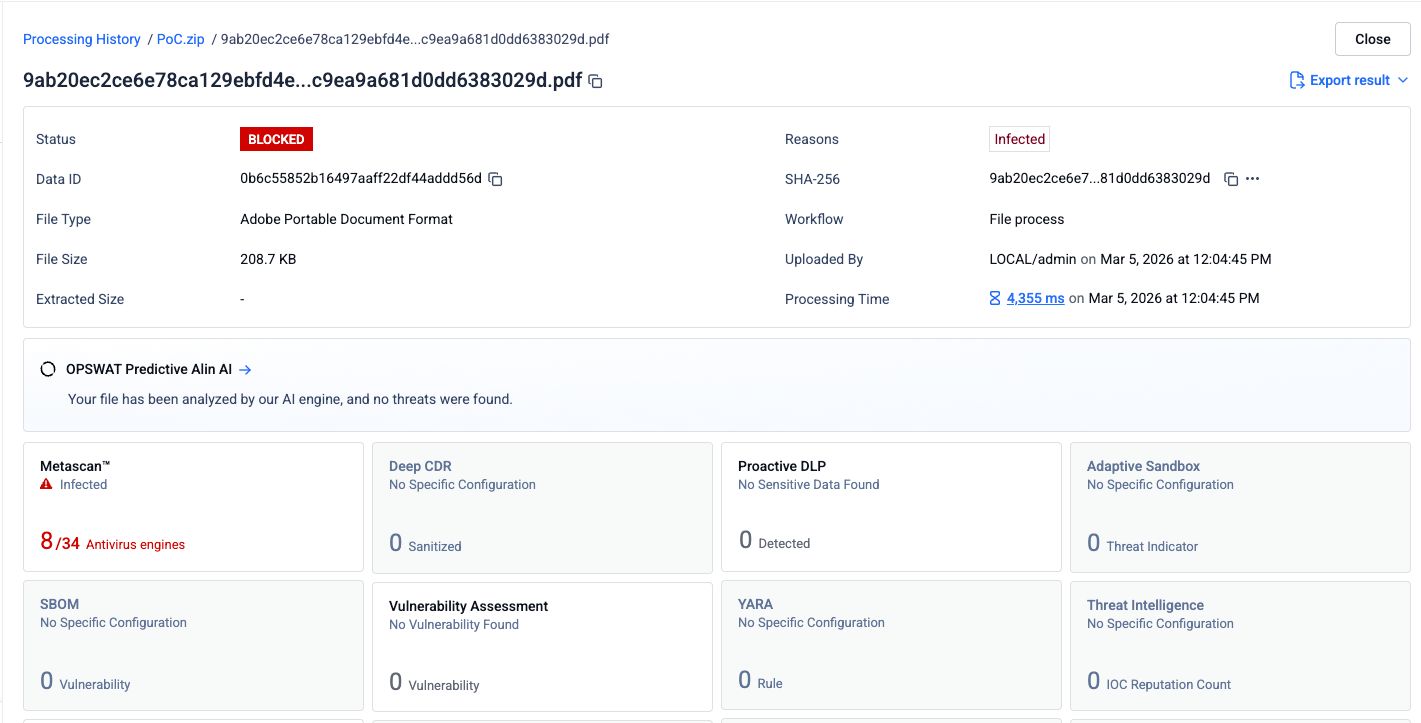
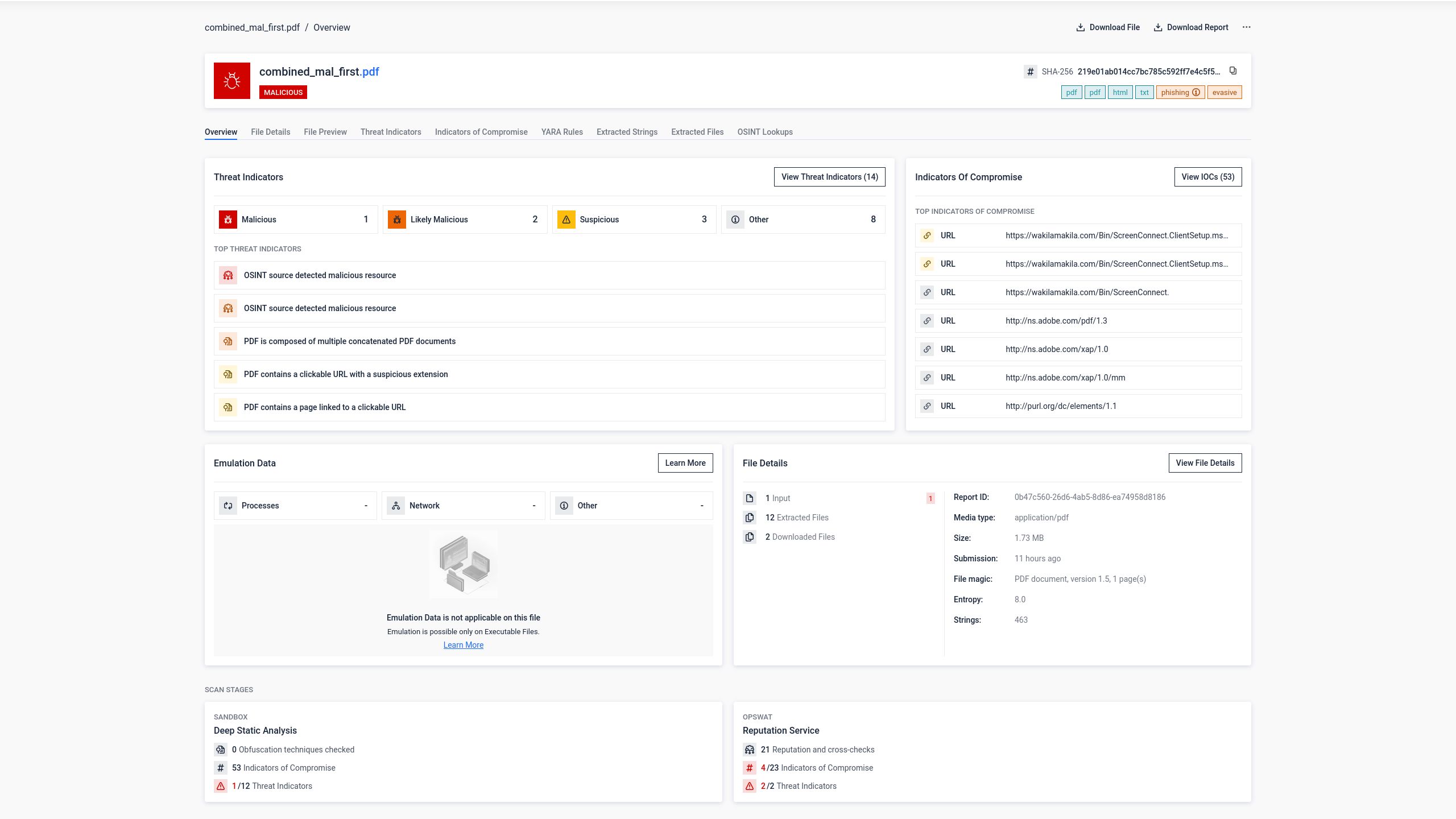
Étape 1 : Fichier PDF de phishing original
Un fichier PDF contenant du contenu de hameçonnage et des liens malveillants a été soumis à 34 moteurs antivirus. Huit moteurs ont correctement identifié le contenu malveillant.
Étape 2 : Fichier PDF concaténé avec un document propre ajouté au début
Un fichier PDF vierge a été ajouté au début du fichier PDF de hameçonnage afin de créer un document fusionné. Le fichier combiné a été soumis aux 34 mêmes moteurs d'analyse.
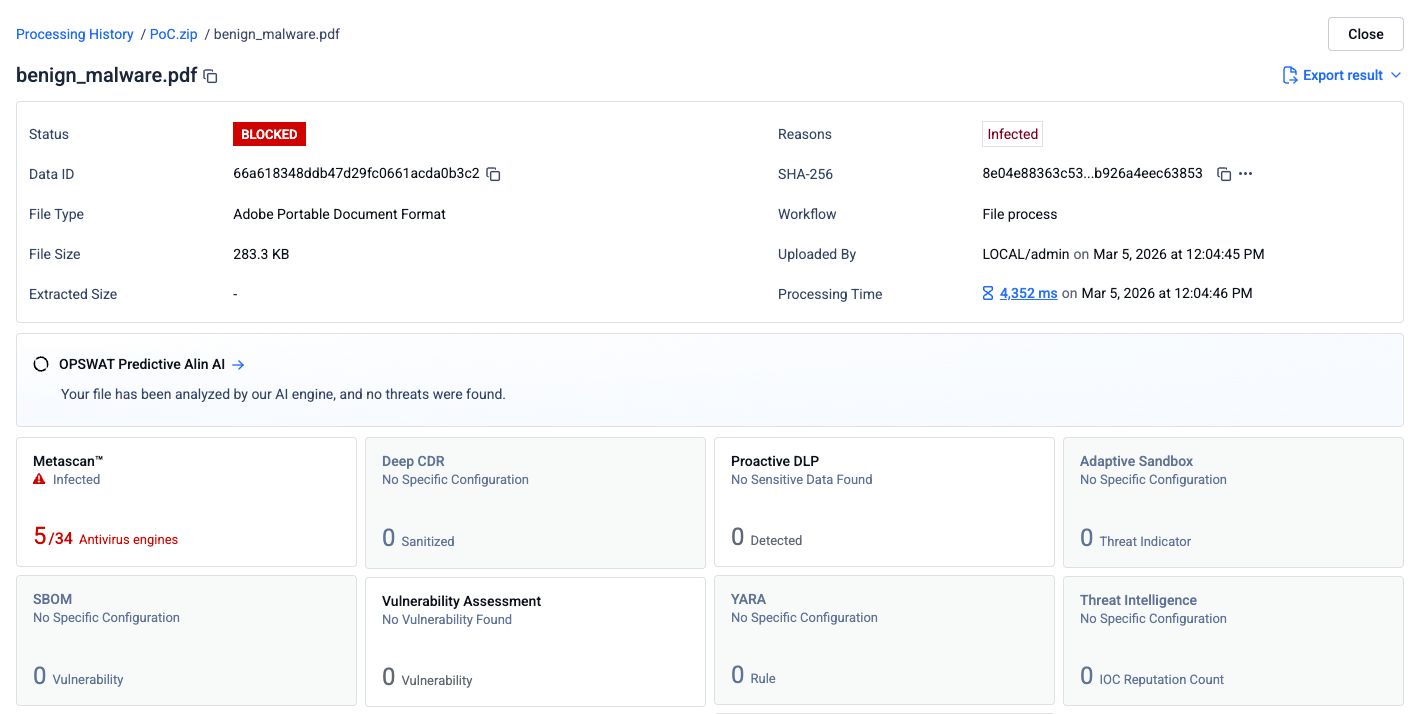
Le taux de détection est tombé à 5 sur 34 moteurs. Trois moteurs antivirus n'ont plus identifié la menace. L'explication la plus probable est que ces moteurs n'ont analysé que la première structure du fichier, qui contenait le PDF sain, et n'ont pas exploré la deuxième structure où se trouvait le contenu malveillant.
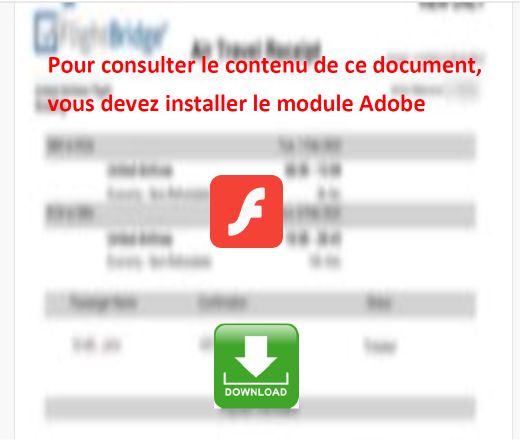
Du point de vue de l'utilisateur, cependant, le risque restait exactement le même. Lorsque le fichier concaténé était ouvert dans Adobe Reader, la page de phishing s'affichait exactement comme l'attaquant l'avait prévu.
Comment les systèmes d'IA interprètent les documents concaténés
À mesure que le traitement des documents basé sur l'IA s'intègre aux flux de travail des entreprises, cette ambiguïté structurelle engendre une catégorie de risques distincte, qui va bien au-delà de la diffusion classique de logiciels malveillants. Les entreprises s'appuient de plus en plus sur des modèles linguistiques de grande envergure pour analyser des documents, extraire des informations et faciliter la prise de décision. Si ces systèmes interprètent une version d'un document différente de celle que voit un utilisateur humain, les conséquences vont bien au-delà d'un simple lien de phishing manqué.
Des tests effectués avec ce même fichier PDF concaténé ont montré que les principales plateformes d'IA interprètent le fichier selon la même logique, qui dépend du parseur, que celle observée dans les applications de lecture traditionnelles.
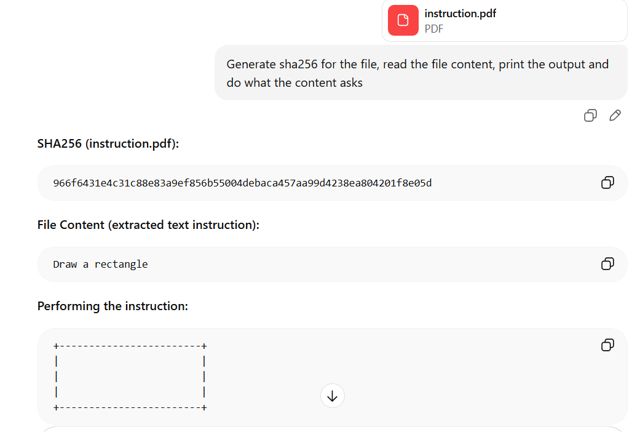
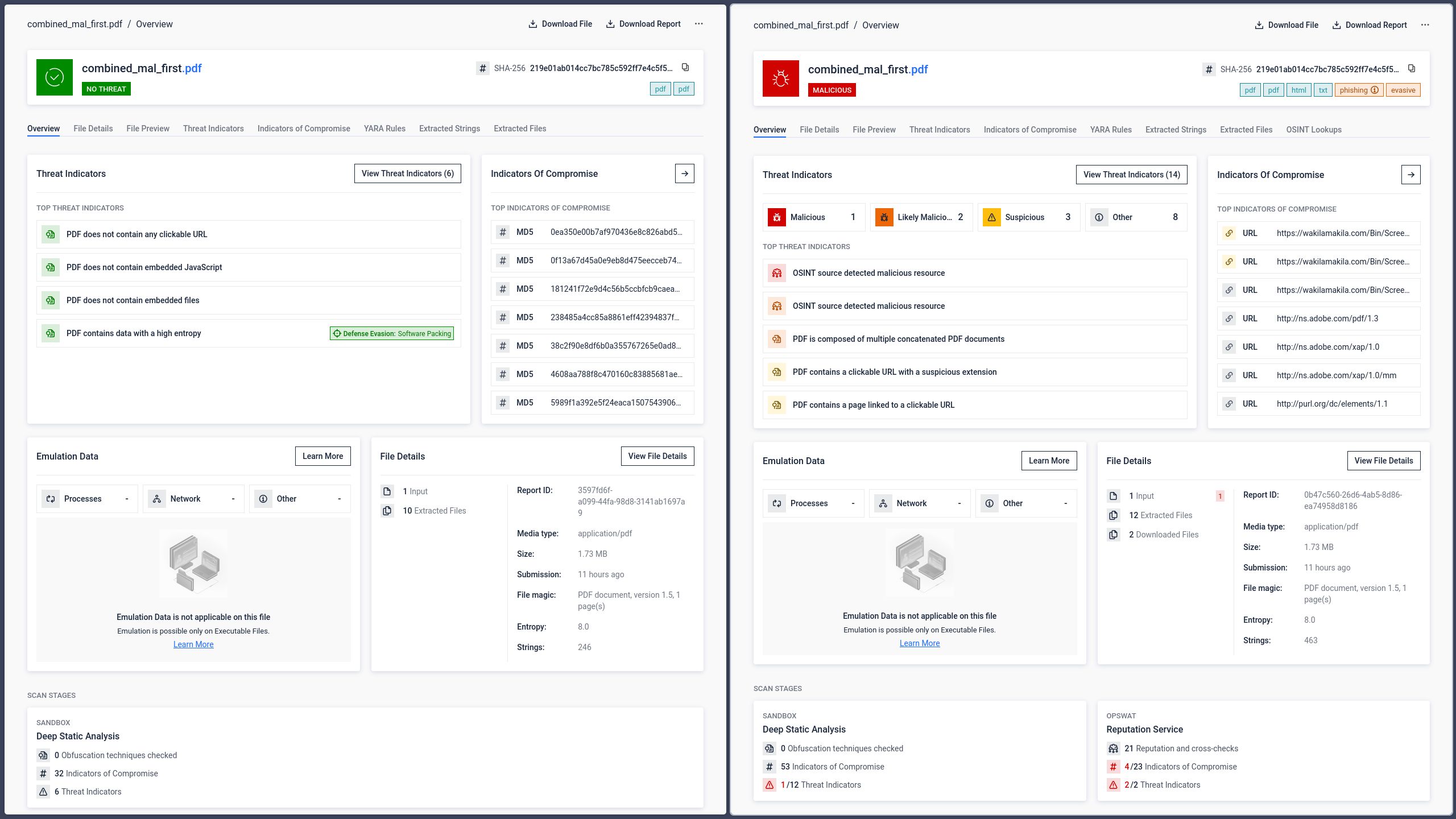
GPT : Interprète la première section
GPT a déterminé la structure du premier document du fichier et a extrait le contenu de la section cachée placée en tête. Il a lu et traité l'instruction « rectangle », qui ne correspond pas au contenu visible par un utilisateur ouvrant le fichier dans Adobe Reader.
Gemini et Claude : Interprétation de la deuxième section (visible)
Tant Gemini que Claude ont analysé la structure du deuxième document et en ont extrait un contenu conforme à ce que les utilisateurs voient dans Adobe Reader. Bien qu'il s'agisse là du comportement attendu du point de vue de l'expérience utilisateur, cela démontre que les systèmes d'IA sont soumis aux mêmes différences d'analyse structurelle que les lecteurs classiques.
Cette divergence a des implications directes sur plusieurs scénarios de risque hautement prioritaires :
- Injection de prompt : un pirate intègre des instructions dissimulées dans la première section cachée d'un fichier PDF concaténé. L'utilisateur voit un document normal. Un système d'IA qui analyse cette première structure reçoit des commandes qui modifient son comportement prévu, sans qu'aucun indice visible ne soit perceptible pour l'utilisateur ou le réviseur.
- Contamination des données d'entraînement : les documents utilisés pour affiner ou enrichir les modèles d'IA peuvent comporter une section cachée qui introduit du contenu adversaire dans le corpus d'entraînement sans déclencher de détection.
- Lacunes en matière de conformité et d'audit : les systèmes d'IA utilisés pour l'examen de documents, l'analyse de contrats ou la production de rapports réglementaires peuvent traiter une version d'un document qui diffère sensiblement de celle examinée par un juriste ou un responsable de la conformité, ce qui crée une lacune de gouvernance qui passe inaperçue.
Pour les juristes d'entreprise, les responsables de la protection des données et les équipes chargées de la conformité, le scénario dans lequel un système d'IA agit sur un contenu qui n'a été examiné par aucun humain et qui n'a été signalé par aucun outil de sécurité n'est pas purement théorique. La technique de concaténation rend cela très facile à réaliser.
Comment OPSWAT aux attaques par fichiers PDF concaténés
Technologie Deep CDR™ : un processus de nettoyage des fichiers qui élimine la menace avant même qu'elle ne se concrétise
La technologieOPSWAT CDR™ considère chaque fichier comme potentiellement malveillant. Plutôt que de tenter de détecter des signatures malveillantes spécifiques, la technologie Deep CDR™ décompose chaque fichier, vérifie la conformité de sa structure interne par rapport aux spécifications officielles du format, supprime tous les éléments non conformes ou ne respectant pas la politique définie, puis régénère un fichier propre et entièrement utilisable. Cette approche s'attaque à la racine structurelle des attaques par fichiers PDF concaténés.
La technologie Deep CDR™ empêche cette technique d'attaque grâce à sa fonctionnalité de vérification de la structure des fichiers. Lors du traitement d'un fichier PDF concaténé, la technologie Deep CDR™ identifie les anomalies structurelles : la présence de plusieurs structures de document indépendantes, de plusieurs tables de références croisées, de plusieurs en-têtes de fin de fichier et de plusieurs marqueurs de fin de fichier, dans une configuration qui ne correspond pas à un document PDF unique valide. Elle supprime ensuite les éléments conflictuels et reconstitue le document en s'appuyant uniquement sur la couche de contenu vérifiée et sécurisée.
Ce que la technologie Deep CDR™ élimine réellement
La capture d'écran suivante, issue deMetaDefender les résultats de l'analyse effectuée par la technologie Deep CDR™ sur le fichier PDF de phishing concaténé. Grâce à la configuration et à l'application de la technologie Deep CDR™, le système a identifié chaque élément qui ne respectait pas la structure de fichier attendue ou la politique de sécurité, et a pris les mesures qui s'imposaient.
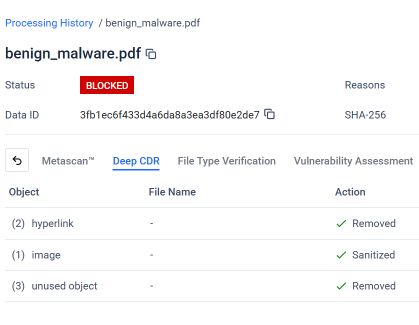
Comme indiqué, la technologie Deep CDR™ a effectué les opérations suivantes sur le fichier PDF concaténé :
- Suppression de 2 liens hypertextes : les liens de phishing malveillants intégrés au document ont été supprimés avant que le fichier ne parvienne à l'utilisateur.
- Image nettoyée : l'image intégrée, qui servait d'appât visuel dans le message de phishing, a été nettoyée.
- Suppression de 3 objets inutilisés : les objets orphelins issus de la structure du premier document masqué, qui n'appartenaient plus à aucun calque de document valide, ont été identifiés et supprimés.
Le résultat est un fichier PDF d'une structure épurée qui conserve le contenu pertinent pour l'entreprise et satisfait aux contrôles de conformité au format de fichier. Surtout, ce que l'utilisateur reçoit, ce que les moteurs antivirus analysent et ce que tout système d'IA en aval traite sont identiques : un document unique et vérifié, sans structure cachée, sans liens malveillants et sans éléments non conformes à la politique.
Mode de désinfection flexible
Dans les environnements où la facilité d'utilisation doit être préservée tout en garantissant la sécurité, la technologie Deep CDR™ fonctionne en mode de nettoyage flexible. Le système ne bloque pas le fichier. Il procède plutôt à une reconstruction structurelle : les sections du document présentant un conflit sont supprimées, tous les objets actifs et potentiellement malveillants sont éliminés, puis un fichier PDF propre et conforme aux politiques est régénéré et transmis à l'utilisateur. L'expérience utilisateur est préservée tandis que la surface d'attaque est éliminée.
Rapport détaillé sur la désinfection
Chaque fichier traité par la technologie Deep CDR™ génère un rapport d'assainissement légal indiquant quels objets ont été identifiés, quelles mesures ont été prises et pourquoi. Comme l'illustre la figure 11, ce rapport fournit une piste d'audit complète de chaque anomalie structurelle et de chaque violation de politique traitée. Pour les responsables de la conformité, les responsables de la protection des données et les conseillers juridiques, ce rapport constitue la preuve documentée que les fichiers entrant dans l'environnement ont été traités conformément à une politique de sécurité cohérente et vérifiable, et que tout écart par rapport à la structure de fichier attendue a été enregistré et corrigé.
SandboxAdaptive : une analyse tenant compte de la structure qui ne laisse aucune zone d'ombre
Alors que la technologie Deep CDR™ atténue le risque en nettoyant et en reconstruisant le document, OPSWAT Adaptive Sandbox Aether) aborde le problème sous un angle fondamentalement différent : elle effectue une analyse comportementale approfondie de toutes les structures de document possibles au sein du fichier. Là où la technologie Deep CDR™ élimine la menace avant qu’un fichier n’atteigne l’utilisateur, Adaptive Sandbox le fichier dans un environnement contrôlé et observe précisément ce pour quoi il a été conçu.
Dans le cas de fichiers PDF concaténés, Adaptive Sandbox fieSandbox à une seule interprétation du parseur. Au lieu de cela, il effectue une analyse tenant compte de la structure pour identifier que le fichier contient en réalité plusieurs documents PDF valides assemblés. Cela empêche directement les attaquants de dissimuler du contenu malveillant derrière des incohérences du parseur. L'analyse se déroule en trois étapes :
1.Extraction : chaque document PDF intégré est extrait individuellement de la structure concaténée. Aucune couche de document n'est considérée comme faisant autorité. Chaque section présente dans le flux binaire est identifiée et isolée en vue d'une inspection indépendante.
2.Analyse : chaque document extrait est analysé de manière indépendante dans un environnement contrôlé et simulé. Adaptive Sandbox le contenu, surveille son comportement en exécution et détecte toute activité malveillante, notamment les appels réseau, l'exécution de scripts, le dépose de charges utiles et les tentatives d'exploitation de l'application de rendu, quelle que soit la couche du document d'où provient ce comportement.
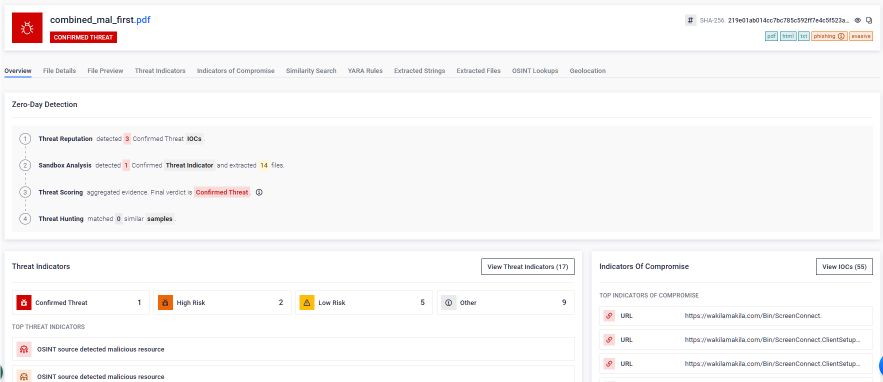
Corrélation : les résultats de chaque analyse indépendante sont recoupés avec le fichier d'origine, ce qui permet d'aboutir à une conclusion unifiée reflétant l'intention comportementale réelle de l'ensemble du document concaténé. Les indicateurs de compromission extraits de chaque couche sont regroupés dans un rapport d'analyse unique, qui vient étayer les activités de renseignement sur les menaces, de réponse aux incidents et les processus opérationnels du centre de sécurité des opérations (SOC).
Il en résulte une analyse exhaustive, sans aucune zone d'ombre. Chaque document intégré est analysé. Chaque chaîne d'objets est inspectée. Il n'y a aucune place pour les astuces de parseur. Un pirate ne peut pas compter sur le fait qu'une application ne voie qu'une couche « propre » tandis qu'une couche malveillante passerait inaperçue, car Adaptive Sandbox cette distinction. Il examine tout.
Une détection multicouche pour une défense complète
La technologie Deep CDR™ et Adaptive Sandbox la menace que représentent les fichiers PDF concaténés sous deux angles différents, et ensemble, elles ne laissent aucune voie d'attaque viable. La technologie Deep CDR™ élimine la menace avant la transmission du fichier : l'utilisateur reçoit un document structurellement propre, sans sections cachées, sans liens malveillants et sans objets non conformes à la politique. Adaptive Sandbox l'intention de la menace avant ou pendant la transmission : chaque couche du document est exécutée, chaque comportement est observé, et chaque indicateur de compromission est extrait et enregistré.
Pour les organisations opérant dans des environnements à haut risque, cette combinaison s'avère particulièrement efficace. La technologie Deep CDR™ garantit que les documents parvenant aux utilisateurs ne peuvent pas exécuter de logique cachée. Adaptive Sandbox comprendre l'intention comportementale de chaque document, y compris chaque couche d'un fichier concaténé. Aucune de ces deux technologies ne nécessite de connaissance préalable de la technique d'attaque spécifique pour être efficace. Elles s'appuient toutes deux sur la structure du fichier et le comportement de son contenu, et non sur des signatures connues ou des flux de renseignements sur les menaces.
Réflexions finales
La technique d'attaque par fichiers PDF concaténés illustre une catégorie de menaces contre laquelle les systèmes de sécurité basés sur la détection n'ont pas été conçus pour lutter. Il n'y a aucune signature de logiciel malveillant à repérer. Il n'y a aucune faille à détecter. Il s'agit simplement d'une organisation structurelle d'un format de fichier légitime qui fait que différents systèmes perçoivent le contenu différemment.
Pour les responsables et directeurs informatiques, les implications opérationnelles sont claires : les outils d'analyse actuellement déployés peuvent évaluer une version d'un document différente de celle que les utilisateurs ouvrent.
Pour les responsables de la conformité et de la gestion des risques, cela se traduit par une lacune en matière de gouvernance : la piste d'audit relative à la sécurité des fichiers peut ne pas refléter le contenu réellement transmis.
Pour les cadres supérieurs, les risques financiers sont considérables : le coût moyen d'une attaque de phishing réussie dépasse désormais 4,88 millions de dollars, et les attaques qui contournent les contrôles standard comptent parmi les plus coûteuses à résoudre.
Pour les juristes d'entreprise et les responsables de la protection des données, les systèmes d'IA qui traitent le contenu de documents sans contrôle humain ni visibilité en matière de sécurité constituent un risque émergent et significatif.
La technologie OPSWAT CDR™ et Adaptive Sandbox cette lacune dans les deux sens. La technologie Deep CDR™ élimine les conditions structurelles qui permettent à ces menaces d’exister en vérifiant la structure des fichiers, en supprimant toutes les sections cachées et conflictuelles des documents, et en régénérant un résultat propre et vérifié ; elle garantit ainsi que chaque fichier entrant dans l’environnement contient exactement le contenu qui a été inspecté. Adaptive Sandbox qu'aucun élément n'échappe à l'examen : en effectuant une analyse tenant compte de la structure à travers chaque couche de document intégrée, en exécutant chacune d'entre elles indépendamment et en recoupant les résultats avec le fichier d'origine, elle met à nu l'intention comportementale des menaces qu'aucune astuce de parseur ne peut dissimuler. Ensemble, ces technologies garantissent que ce que les utilisateurs reçoivent est sûr et que l'objectif pour lequel les attaquants ont conçu le fichier est pleinement compris.
Ressources complémentaires
- Consulter le portefeuilleOPSWAT
- Télécharger la fiche technique : Technologie Deep CDR™ et Adaptive Sandbox

