L'usurpation de fichier reste l'une des techniques les plus efficaces utilisées par les attaquants pour contourner les contrôles de sécurité traditionnels. L'année dernière, OPSWAT a introduit un moteur de détection des types de fichiers amélioré par l'IA afin de combler les lacunes laissées par les outils existants. Cette année, avec File Type Detection Model v3, nous avons amélioré cette capacité en nous concentrant sur les types de fichiers pour lesquels la précision est la plus importante, et où les systèmes traditionnels basés sur la logique échouent systématiquement.
Le modèle de détection de type de fichier v3 d'OPSWAT est conçu pour relever un défi spécifique, à savoir la classification fiable de fichiers ambigus et non structurés, en particulier les formats textuels tels que les scripts, les fichiers de configuration et le code source. Contrairement aux classificateurs généralistes, ce modèle a été spécialement conçu pour les cas d'utilisation dans le domaine de la cybersécurité, où une classification erronée d'un script shell ou l'absence de détection d'un document contenant des macros intégrées, tel qu'un fichier Word contenant du code VBA, peut présenter un risque important pour la sécurité.
Pourquoi la détection des vrais types de fichiers est essentielle
La plupart des systèmes de détection reposent sur trois approches communes :
- Extension de fichier : Cette méthode vérifie le nom du fichier pour en déterminer le type en fonction de l'extension, par exemple .doc ou .exe. Elle est rapide et largement compatible avec toutes les plateformes. Cependant, elle est facilement manipulable. Un fichier malveillant peut être renommé avec une extension d'apparence sûre, et certains systèmes ignorent totalement les extensions, ce qui rend cette approche peu fiable.
- Octets magiques : Il s'agit de séquences fixes que l'on trouve au début de nombreux fichiers structurés, tels que les PDF ou les images. Cette méthode améliore la précision par rapport aux extensions de fichiers en examinant le contenu réel du fichier. L'inconvénient est que tous les types de fichiers n'ont pas de motifs d'octets bien définis. Les octets magiques peuvent également être usurpés et des normes incohérentes d'un outil à l'autre peuvent prêter à confusion.
- Analyse de la distribution des caractères : Cette méthode analyse le contenu réel d'un fichier pour en déduire le type. Elle est particulièrement utile pour identifier les formats textuels peu structurés, tels que les scripts ou les fichiers de configuration. Bien qu'elle permette d'obtenir des informations plus approfondies, elle s'accompagne de coûts de traitement plus élevés et peut produire des faux positifs en cas de contenu inhabituel. Elle est également moins efficace pour les fichiers binaires qui ne présentent pas de motifs de caractères lisibles.
Ces méthodes fonctionnent bien pour les formats structurés, mais deviennent peu fiables lorsqu'elles sont appliquées à des fichiers non structurés ou textuels. Par exemple, un script shell avec des commandes minimales peut ressembler de près à un fichier texte. Bon nombre de ces fichiers n'ont pas d'en-têtes solides ou de marqueurs cohérents, ce qui rend insuffisante la classification basée sur des modèles d'octets ou des extensions. Les attaquants exploitent cette ambiguïté pour déguiser des scripts malveillants en documents ou journaux inoffensifs.
Les anciens outils tels que TrID et LibMagic n'ont pas été conçus pour ce niveau de nuance. Bien qu'ils soient efficaces pour la catégorisation générale des fichiers, ils ont été optimisés pour l'étendue et la vitesse, et non pour la détection spécialisée dans le cadre de contraintes de sécurité.
Fonctionnement du modèle de détection de type de fichier v3
Le processus de formation du modèle de détection de type de fichier v3 se compose de deux étapes. Lors de la première étape, un pré-entraînement adapté au domaine est effectué à l'aide de la modélisation du langage masqué (MLM), ce qui permet au modèle d'apprendre la syntaxe et les modèles structurels spécifiques au domaine. Lors de la deuxième étape, le modèle est affiné sur un ensemble de données supervisé dans lequel chaque fichier est explicitement annoté avec son véritable type de fichier.
L'ensemble des données est un mélange de fichiers réguliers et d'échantillons de menaces, ce qui garantit un bon équilibre entre la précision du monde réel et la pertinence de la sécurité. OPSWAT conserve le contrôle des données d'entraînement, ce qui permet d'affiner en permanence les formats les plus importants pour les opérations de sécurité.
La composante IA est appliquée avec précision, et non de manière générale. Le modèle de détection de type de fichier v3 se concentre sur les types de fichiers ambigus et non structurés que les méthodes de détection traditionnelles ne peuvent pas traiter efficacement, tels que les scripts, les journaux et les textes peu structurés où la structure est incohérente ou absente. Le temps d'inférence moyen reste inférieur à 50 millisecondes, ce qui le rend efficace pour les flux de travail en temps réel à travers les téléchargements de fichiers sécurisés, l'application des points finaux et les pipelines d'automatisation.
Résultats de l'évaluation comparative
Nous avons comparé le moteur de détection des types de fichiers d'OPSWAT aux principaux outils de détection des types de fichiers en utilisant un ensemble de données vaste et diversifié. La comparaison a porté sur les scores F1 de 248 000 fichiers et d'environ 100 types de fichiers.
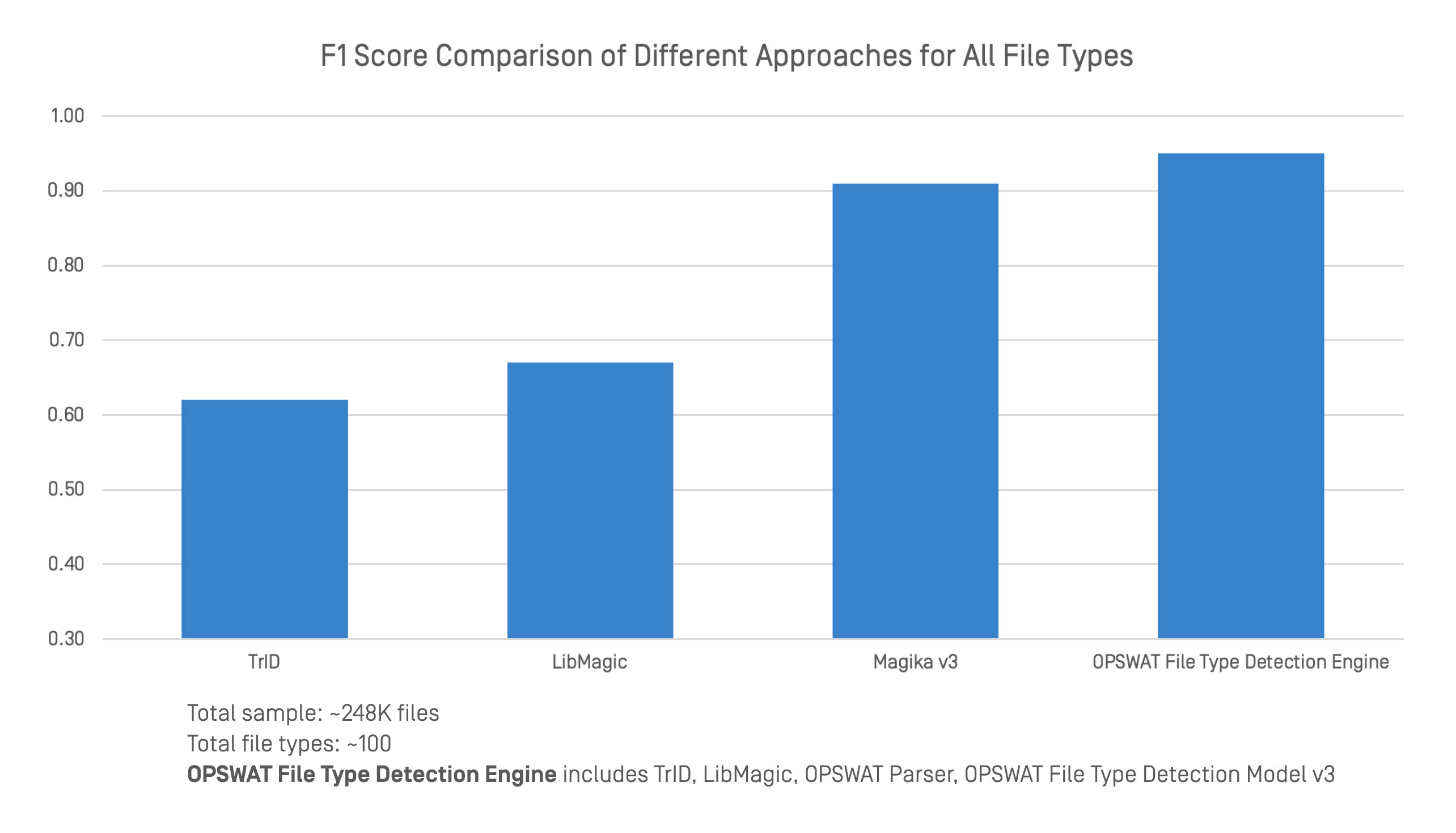
Le moteur de détection de type de fichier d'OPSWAT intègre plusieurs techniques, dont TrID, LibMagic et les technologies propres à OPSWATtelles que les analyseurs avancés et le modèle de détection de type de fichier v3. Cette approche combinée permet une classification plus forte et plus fiable des formats structurés et non structurés.
Lors des tests de référence, le moteur a obtenu une précision globale supérieure à celle de n'importe quel outil pris isolément. Si TrID, LibMagic et Magika v3 sont performants dans certains domaines, leur précision diminue lorsque les en-têtes de fichiers sont manquants ou que le contenu est ambigu. En combinant la détection traditionnelle et l'analyse approfondie du contenu, OPSWAT maintient des performances constantes même lorsque la structure est faible ou intentionnellement trompeuse.
Fichiers texte et script
Les formats de texte et de script sont souvent impliqués dans les menaces véhiculées par les fichiers et les déplacements latéraux. Nous avons effectué un test ciblé sur 169 000 fichiers dans des formats tels que .sh, .py, .ps1, et .conf.
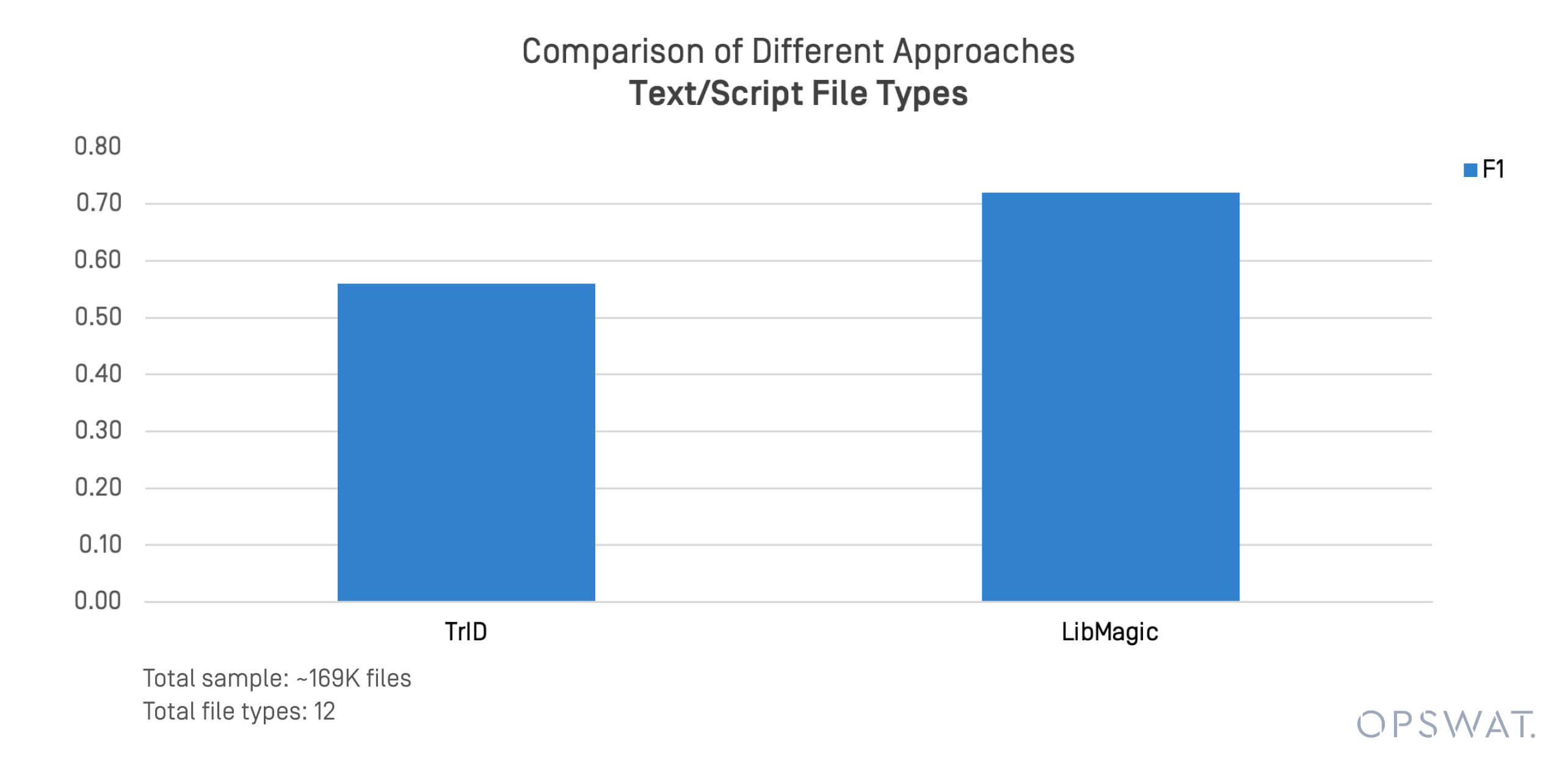
TrID et LibMagic ont montré des limites dans la détection de ces fichiers non structurés. Leurs performances se dégradent rapidement lorsque le contenu des fichiers s'écarte des modèles d'octets attendus.
Modèle de détection de type de fichier v3 vs Magika v3
Nous avons évalué le modèle de détection de type de fichier v3 d'OPSWAT par rapport à Magika v3, le classificateur d'IA open-source de Google, sur 30 types de fichiers texte et script en utilisant le même ensemble de données de 500 000 fichiers.
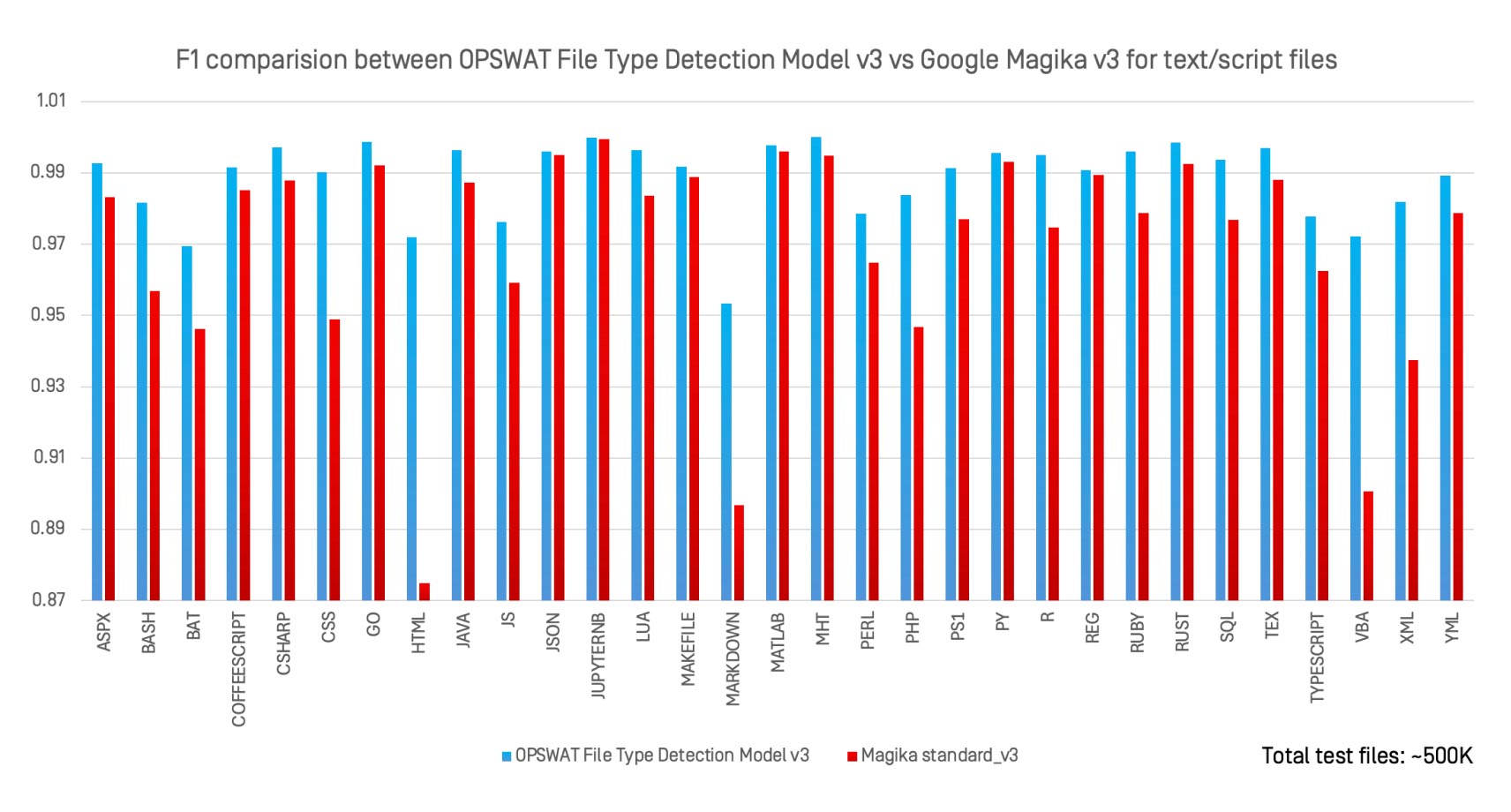
Principales observations :
- Le modèle de détection des types de fichiers v3 a égalé ou dépassé les performances de Magika pour la quasi-totalité des formats.
- Les plus fortes progressions ont été observées dans des formats peu définis tels que
.bat, .perl, .html,et .xml. - Contrairement à Magika, qui est conçu pour l'identification générale, File Type Detection Model v3 est optimisé pour les formats à haut risque, pour lesquels une mauvaise classification a de sérieuses implications en termes de sécurité.
Principaux cas d'utilisation
Chargements, téléchargements et transferts de fichiers Secure
Empêchez les fichiers déguisés ou malveillants de pénétrer dans votre environnement par le biais de portails web, de pièces jointes ou de systèmes de transfert de fichiers. La détection améliorée par l'IA va au-delà des extensions et des en-têtes MIME pour identifier les scripts, les macros ou les exécutables intégrés dans les fichiers renommés.
Pipelines DevSecOps
Arrêtez les artefacts dangereux avant qu'ils ne contaminent vos environnements de développement ou de déploiement de logiciels. En validant le véritable type de fichier à partir du contenu réel, MetaDefender Core s'assure que seuls les formats approuvés circulent dans les pipelines CI/CD, réduisant ainsi le risque d'attaques de la chaîne d'approvisionnement et maintenant la conformité avec les pratiques de développement sécurisées.
Contrôle de la conformité
La détection précise des types de fichiers est essentielle pour répondre aux mandats réglementaires tels que HIPAA, PCI DSS, GDPR et NIST 800-53, qui exigent un contrôle strict de l'intégrité des données et de la sécurité des systèmes. La détection et le blocage des types de fichiers usurpés ou non autorisés permettent d'appliquer des politiques qui empêchent l'exposition des données sensibles, de maintenir la préparation à l'audit et d'éviter des pénalités coûteuses.
Réflexions finales
Les classificateurs de fichiers à usage général tels que Magika sont utiles pour la catégorisation générale des contenus. Mais en matière de cybersécurité, la précision compte plus que la couverture. Un seul script mal classé ou une seule macro mal étiquetée peut faire la différence entre l'endiguement et la compromission.
Le moteur de détection des types de fichiers d'OPSWAT offre cette précision. En combinant l'analyse des types de fichiers améliorée par l'IA avec des méthodes de détection éprouvées, il fournit une couche de classification fiable là où les outils traditionnels échouent, en particulier dans les formats ambigus ou non structurés. Il ne s'agit pas de tout remplacer, mais de renforcer les points faibles critiques de votre pile de sécurité grâce à une détection contextuelle en temps réel.

