À l'adresse OPSWAT, nous accordons une grande importance à l'innovation, à la créativité et à l'amélioration continue lorsque nous développons des solutions avancées pour protéger les infrastructures critiques et les organisations contre les cybermenaces. Ces valeurs nous ont inspirés pour créer le OPSWAT MetaDefender Threat Intelligence , qui nous permet de mieux comprendre et détecter les cybermenaces en évolution afin de détecter et d'identifier les fichiers similaires.
Les variantes de logiciels malveillants devenant de plus en plus sophistiquées et évasives, les solutions antivirus traditionnelles basées sur les signatures sont insuffisantes. Pour relever ce défi, les experts en cybersécurité de OPSWAT ont mis au point une solution élégante qui s'appuie sur une technologie d'analyse statique de pointe et sur l'apprentissage automatique pour identifier les similitudes entre les fichiers. Cette approche constitue un moyen efficace d'atténuer les risques de cybersécurité et de prévenir les attaques potentielles.
La création du site MetaDefender Threat Intelligence nous a donné l'occasion de nous attaquer à un problème difficile et urgent. Nous avons pu développer des solutions de cybersécurité efficaces qui fournissent aux organisations les informations dont elles ont besoin pour anticiper les menaces émergentes et s'y préparer. Cela correspond à notre culture de l'innovation et à notre engagement à fournir la meilleure protection possible à nos clients.

Les données
Pour effectuer des recherches par similarité, les fichiers sont soumis à un processus d'analyse rigoureux utilisant les technologies d'analyse statique et d'émulation de fichiers MetaDefender . Cette technologie de pointe extrait les informations les plus pertinentes et les plus utiles d'un fichier donné.
Nos analystes experts en logiciels malveillants ont déterminé les fonctionnalités les plus efficaces pour calculer les similitudes entre deux fichiers. Ces fonctions sont soigneusement sélectionnées en fonction de leur capacité à fournir des résultats précis et pertinents, et elles sont continuellement mises à jour pour rester en phase avec les dernières tendances et techniques en matière de logiciels malveillants.
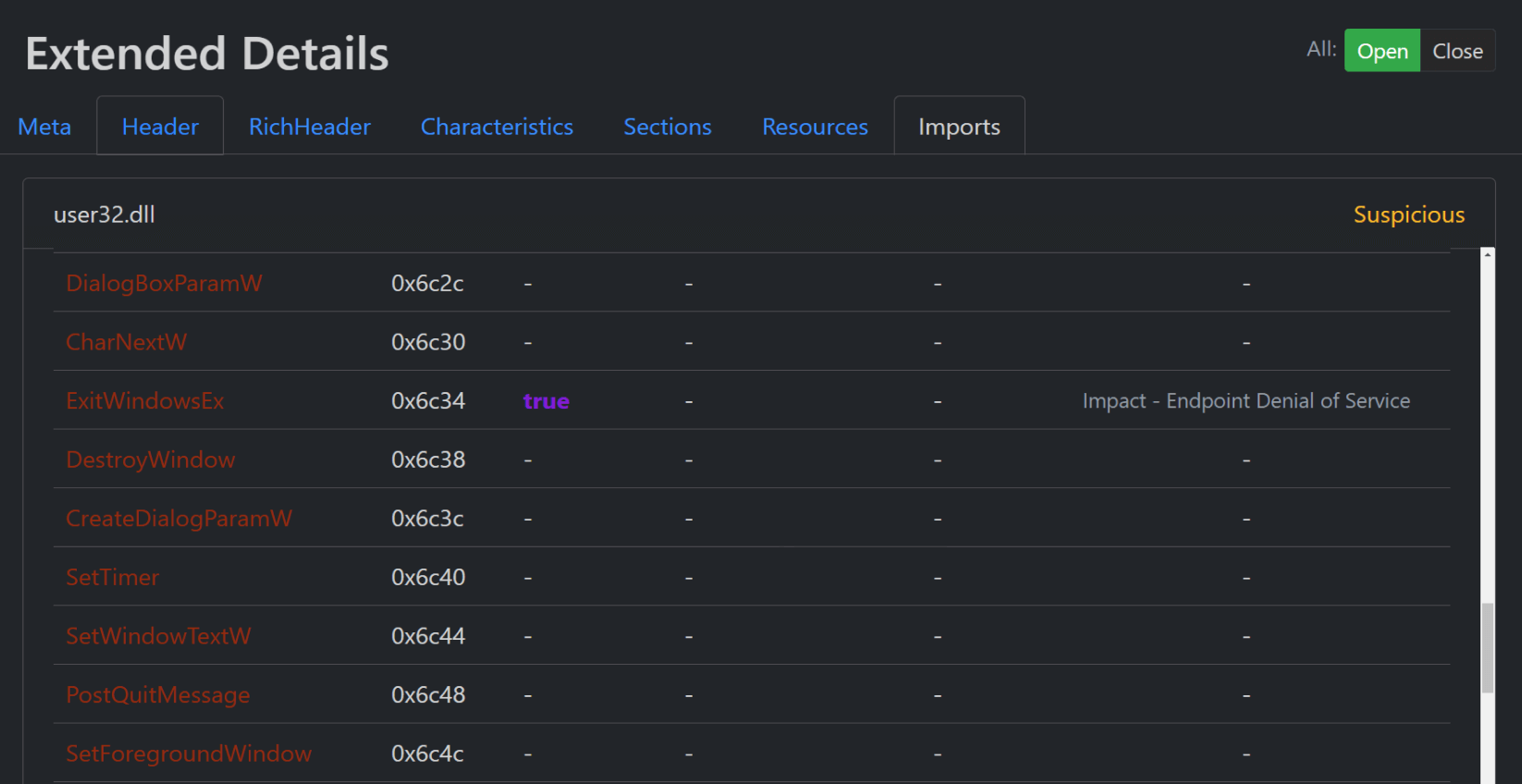
En voici quelques caractéristiques :
- Métadonnées binaires (taille du fichier, entropie, architecture, caractéristiques du fichier, et bien d'autres)
- Importations
- Ressources
- Sections
- Signaux
- Et plus encore
Remarque : lors de la recherche de similitudes entre des fichiers, il est important d'utiliser les signaux générés par Filescan et de ne pas se fier uniquement au verdict final (malveillant, informatif, etc.) d'un fichier. Cette approche permet d'éviter tout biais potentiel pouvant survenir au cours du processus de recherche de similarités.

Processus
Le processus de recherche de similitudes consiste à extraire et à transformer ces caractéristiques des fichiers exécutables portables (PE) en enregistrements vectoriels. Les encastrements vectoriels représentent les données sous forme de points dans un espace à n dimensions, ce qui permet aux points de données similaires de se regrouper, créant ainsi une empreinte digitale du fichier. Le nombre de dimensions est déterminé par chaque section tout en réduisant la dimensionnalité.
La solution utilise ensuite de multiples calculs de distance modifiés entre ces vecteurs pour trouver les fichiers les plus similaires, ce qui nous permet de répondre à la question "quelle est la similarité entre ce fichier et un autre ?". L'architecture et l'algorithme utilisent des méthodes d'indexation qui garantissent un traitement rapide, même lorsque la recherche porte sur des millions de fichiers. L'analyse algorithmique de ces champs permet à la solution d'identifier et d'isoler avec précision les fichiers similaires et les menaces.
En plus d'une technologie avancée, Similarity Search offre une interface personnalisable qui permet aux utilisateurs de filtrer leurs paramètres de recherche. Cette fonction offre une plus grande flexibilité et garantit que les utilisateurs reçoivent les résultats les plus précis et les plus pertinents pour leurs besoins spécifiques.
Filtres :
- Tags
- Verdict
- Seuil de similarité
Le pipeline
Le processus de pipeline consiste à prendre un nouveau fichier PE d'entrée, tel qu'un exécutable, et à le soumettre à des modèles d'apprentissage automatique qui génèrent des encastrements de vecteurs sur la base de caractéristiques présélectionnées. Ces vecteurs sont ensuite intégrés dans un espace vectoriel, qui peut avoir un nombre quelconque de dimensions.

Nous utilisons diverses mesures de distance pour calculer la similarité entre les vecteurs et les caractéristiques, ce qui nous aide à déterminer le point le plus proche d'un fichier PE d'entrée donné.

Score de similarité
Il convient de noter que les scores de similarité ne sont pas absolus et peuvent être quelque peu subjectifs. Il n'existe pas de formule ou de norme universellement acceptée pour déterminer le degré de similitude entre les fichiers, car celui-ci peut varier en fonction du contexte et du cas d'utilisation spécifique. Il est donc important d'interpréter les scores de similarité avec prudence et de tenir compte de la méthodologie utilisée pour les calculer. La recherche par similarité utilise des poids pour calculer un score de similarité précis.
Résultats MetaDefender
Le résultat du site Filescan fournit des informations complètes sur le fichier utilisé pour la recherche de similarités. Toutefois, il est important d'analyser ces informations en profondeur pour bien comprendre les caractéristiques et les propriétés du fichier. L'interface utilisateur affiche diverses propriétés d'un fichier analysé et génère un rapport détaillé de ses caractéristiques.
Pour accéder à la fonction de recherche de similitudes, naviguez vers le côté gauche de l'interface utilisateur. Par défaut, la fonction de recherche de similitudes est automatiquement lancée avec des paramètres prédéfinis. En outre, les utilisateurs disposent de plusieurs options de filtrage pour les aider à personnaliser leur recherche et à obtenir des résultats optimaux en fonction de leurs besoins spécifiques.
Filtres :
- Étiquettes : Il s'agit d'étiquettes dynamiques attribuées aux fichiers en fonction de leurs attributs. Lors de l'utilisation de la fonction de recherche par similarité, les balises peuvent être utilisées pour étiqueter des fichiers présentant des caractéristiques spécifiques, telles que peexe ou shell32.dll. Les balises facilitent les recherches ciblées et efficaces, permettant aux utilisateurs de trouver rapidement les fichiers qui répondent à leurs besoins spécifiques.
- Verdict : le verdict de Filescan fournit le résultat d'une analyse effectuée sur le fichier, indiquant si le fichier est propre, malveillant ou potentiellement dangereux d'une manière ou d'une autre. En utilisant le verdict Filescan comme filtre, les utilisateurs peuvent affiner leurs résultats de recherche afin d'exclure les fichiers signalés comme malveillants ou suspects.
- Seuil de similarité : Il s'agit d'un paramètre configurable qui détermine le niveau minimum de similarité nécessaire pour que les fichiers soient inclus dans les résultats de la recherche. En ajustant ce seuil, les utilisateurs peuvent personnaliser les résultats de leur recherche en fonction de leurs besoins spécifiques. Par exemple, ils peuvent trouver des fichiers qui sont étroitement liés ou ceux qui ont un lien plus ténu. Ce filtre est utile pour les utilisateurs qui ont besoin d'équilibrer la précision avec une recherche large et complète.
Onglets
Dans la fonction de recherche par similarité, les utilisateurs se voient proposer des options de filtrage par défaut sous forme d'onglets. Ces onglets permettent aux utilisateurs de filtrer les résultats en fonction des fichiers les plus similaires, des fichiers les plus récents et des fichiers marqués d'un verdict malveillant. Ces options de pré-filtrage sont conçues pour améliorer l'efficacité et la précision de la recherche pour les utilisateurs.

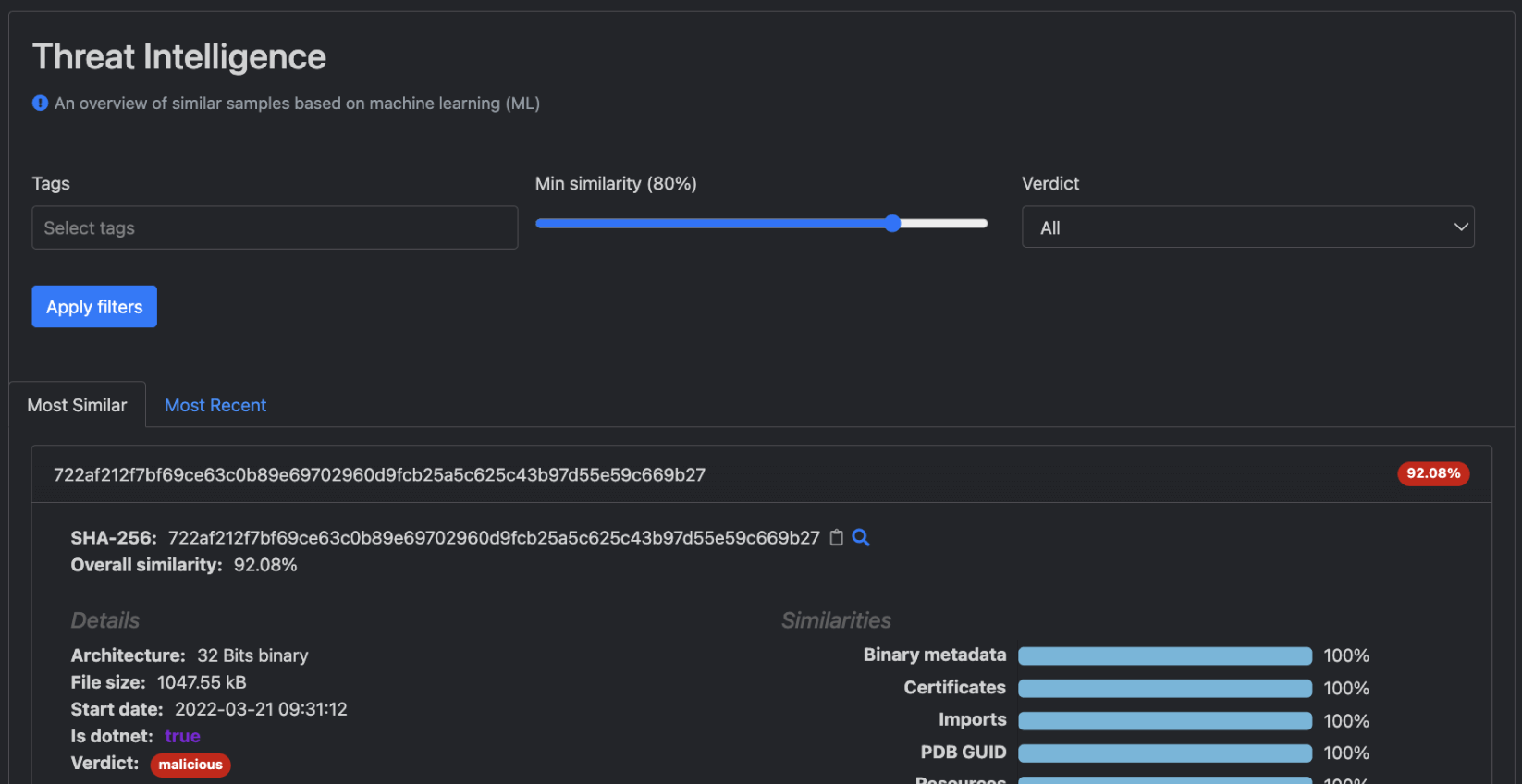
Threat Intelligence Sous-page
La sous-page Threat Intelligence offre aux utilisateurs diverses fonctionnalités, telles que la possibilité d'afficher les fichiers les plus étroitement liés et d'utiliser l'interface utilisateur filtrable. En sélectionnant un identifiant SHA256 spécifique, les utilisateurs peuvent obtenir des informations détaillées sur la similarité du fichier associé, ainsi que des détails de haut niveau.
Principaux cas d'utilisation
Comme pour toute application d'apprentissage automatique, il est essentiel de valider les résultats d'une recherche par similarité. Toutefois, cette fonctionnalité offre aux utilisateurs un large éventail de possibilités pour explorer et identifier efficacement les fichiers pertinents. La recherche par indexation fournit une recherche par hachage exceptionnellement rapide pour tous les types de fichiers et constitue la pierre angulaire du produit. Les entités suivantes peuvent bénéficier de la fonctionnalité de recherche par similarité.
- Les analystes du cyber threat intelligence , qui peuvent tirer parti de cette capacité pour enquêter et détecter les menaces nouvelles et en évolution, améliorant ainsi la position de leur organisation en matière de sécurité.
- Les chasseurs de menaces, qui peuvent rechercher de manière proactive des indicateurs de compromission (IOC) et des vulnérabilités potentielles, anticipant ainsi les activités malveillantes.
- Toute personne intéressée par l'exploration des relations entre les fichiers et l'identification des similitudes, y compris les chercheurs, les enquêteurs et les analystes.
Accéder à la recherche par similarité
Découvrez comment vous pouvez intégrer la recherche de similarités dans vos processus en consultant notre documentation à l'adresse https://www.opswat.com/docs. Veuillez noter que la fonction de recherche de similitudes est un module complémentaire disponible exclusivement pour les utilisateurs de nos offres payantes Filescan ou Threat Intel. Si vous souhaitez explorer cette fonctionnalité, ouvrez un compte dès aujourd'hui !

